层次化强化学习实现综合任务对话策略学习
论文原文链接:Composite Task-Completion Dialogue Policy Learning via Hierarchical Deep Reinforcement Learning
建议先导阅读:当你打海底捞客服的时候-谈谈任务型语音对话
引言
对于旅游规划这种复杂任务而言,由于有酒店机票总价限制或时间先后等制约条件,对话策略的学习就十分富有挑战性。本文在options over MDPs(Markov Decision Process)的数学框架下使用层次化强化学习,通过构建了分两层的对话策略以及全局的状态追踪来试图解决这一问题。本文主要关注综合性任务(composite task),即可被划分为相关子任务的一类复杂任务。
强化学习(reinforcement learning)是解决任务型对话的常见方法,但存在三种常见问题,且该三种问题在多领域任务型对话中更加严重:
| 问题 | 多领域中的挑战 |
|---|---|
| 奖励的稀疏问题 | 更大的状态-行动空间 |
| 槽(对话状态相关的信息槽)约束的满足问题 | 存在领域间交叉约束 |
| 用户体验问题 | 频繁的领域切换 |
本文讲解的方法希望能通过利用任务本身带有的结构信息来试图解决上述问题,通过内置评估模块(evaluation module)来进行内部评价也就是增加内部reward,使得强化学习过程探索更高效,决策空间更小且领域切换次数减少。
实验方面,本文旅游计划任务(Frames数据集)上分别进行了模拟和真人的测试。
相关工作
在任务型对话系统中,强化学习从2000年就开始有了广泛的应用;2016年后深度强化学习(deep reinforcement learning)的出现让特征工程不再必要。
多数相关研究都集中在单领域的任务型对话系统,而从单领域到多领域的推广是非平凡的——更大的状态-动作空间,更长的对话周期以及奖励设计都使得该推广存在挑战。上述困难也是层次化强化学习(将复杂任务递归分解为子任务)的常见问题。为解决该问题,“Hierarchies of machines”、“MAXQ分解”等方法被提出。本文采用options over MDPs这一兼具简洁性与可推广性的数学框架。另外本文所借鉴的层次化DQN在ATARI游戏——”Montezuma’s Revenge”中效果拔群。
另外本文的“综合任务对话”其实有别于多领域任务对话,在本文的讨论环境下,多领域任务型对话指虽然每次对话可能涉及不同领域,但单次对话只会涉及最多一个领域。本文认为多领域这一概念所表示的任务更多的涉及迁移学习与领域选择领域识别。
对话系统构建
整体结构
本文使用的综合任务对话Agent(指代替专业接线员与用户对话的程序功能)包含四部分:
- 语言理解模块
NLU:基于LSTM,负责识别用户意图(intent)和提取槽信息(slot filling)。 - 状态追踪模块
DST:追踪对话状态。 - 对话策略模块
policy:根据对话状态选择下一个对话动作。 - 自然语言生成模块
NLG:将对话动作转换为自然语言表示。
与传统Agent的最大差别在于:传统Agent通常将DST和policy统称为对话管理模块(DM=Dialogue Manager),而本文中的DST是一个全局DST(global dialogue state tracker)。全局DST的好处在于:
- 可以综合所有子任务的状态
- 可以尽量确保满足子任务间的限制
Options over MDPs
马尔可夫决策过程(MDP)
非常负责任的给出了wiki
“允许多步动作”
相比于普通的MDP只能每次只能选一个动作并移动一步,该框架允许“多步动作”(multi-step action)来完成子任务(也就是一个option)。听说这个和决策问题中的semi-Markov decision processes关系不小。
该框架的一个具体例子可见下图:
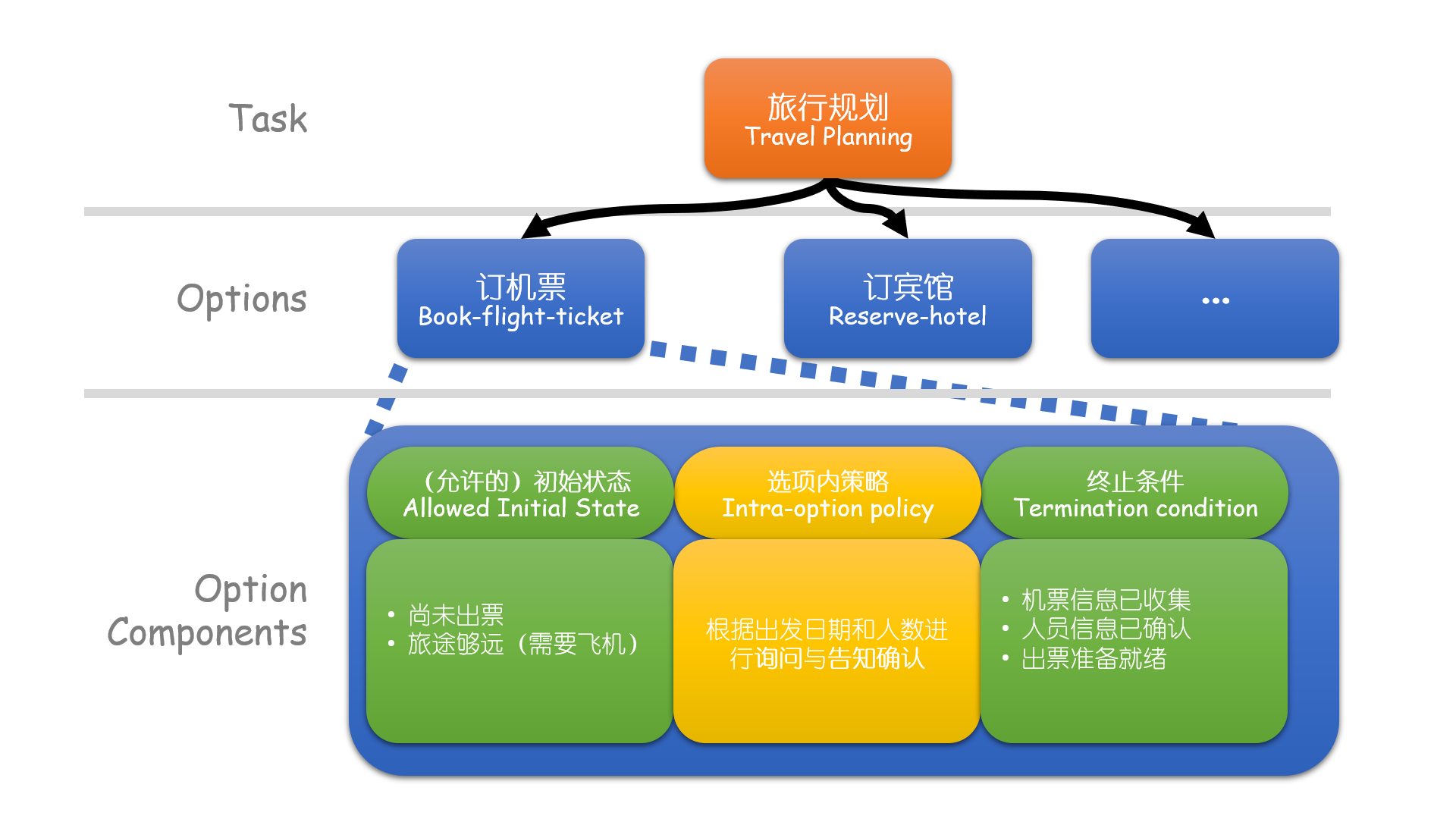
层次化策略学习
“选项内策略”和传统的对话策略没有区别,区别在于选项间的策略(intra-option policy)。本文使用结合深度强化学习和层次化值函数的Agent来学习综合任务对话策略,策略分为两层。
- 顶层策略:根据当前状态选择一个子任务。
- 低层策略:被所有子任务共享
参数,根据当前状态和当前所属的子任务来选择对话动作直到对话状态满足终止条件。
注意上述的“状态”均指代全局状态。另外,内部评价机制会在子任务完成时(推测为rule based判断)给出一定内部奖励(intrinsic reward),该奖励用于优化低层策略而用户模拟器给出的外部奖励(extrinsic reward)用于优化顶层策略。
略去无用的公式,本文的Agent在DQN的使用中:
- 通过SGD(后文又RMSprop)优化Q值的均方误差(MSE)
- 内置了分离目标网络(target network)和经验回放(experience replay)
- Rule-based解决冷启动
训练算法伪代码见论文最下方“附录B”。
用户模拟器
该文用户模拟器的实现借鉴了TC-bot,整体结构大致可分为
- 用户目标生成:通常包含询问槽(用户需要询问系统的信息)和通知槽(用户的已有限制)
- 初始对话生成:通过规则生成用户的第一句话
- 用户日程管理(agenda):和用户目标共同组成用户状态
- 自然语言生成:包含语言模板、错误模型等等
若成功制定旅行计划且满足用户限制则视为对话成功,模拟器会提供外部奖励(extrinsic reward)。
通过输入Frames数据集中的对话,通过一些规则(原文有详细介绍)可以提取一些可用的用户目标;通过将用户目标按照是否包含强限制、倾向于从哪个子任务开始分为不同的用户类型,并在实验中分别测试。
实验
数据集
Frames数据集,具体格式可参见这里的例子和这篇论文。该数据集主要用于用户模拟器的创建。
基线
- Rule:手工构建的复杂规则系统,先询问槽再进行确认。
- Rule+:按照一个优化后的顺序询问槽,平均轮数比Rule长。
- flat RL:只是用外部奖励来构建的传统DQN-agent
模拟用户结果
HRL在成功率、平均轮数和奖励三个指标上,在三种用户类型上的表现均超越三种基线方法,并且有探索更高效、面对更大搜索空间(有软限制的用户模拟)时成功率更高等特点。
真人用户结果
通过作者同事(可能有误差?)等12位真人用户225次对话体验,HRL表现更为自然流畅,主要体现在更少的进行子任务切换。
结语
依照本文的结果,HRL实现的综合对话策略效果不错,超过基线系统。其将来研究方向可考虑:
- 不同类型用户的适配,即个性化对话
- 更多层次的策略(>2)
- 自动识别或划分子任务