为任务型对话构建用户模拟器
论文原文链接:A User Simulator for Task-Completion Dialogues
引言
在用强化学习构建任务型对话系统时,常会碰到一些困难。
- 强化学习需要与环境交互,故传统的语料库不能直接使用。
- 特定任务需要特定标注的数据。
- 标注对话内容需要特定领域的额外知识。
鉴于构建特定合适的数据集费钱费时,一个较好的办法是:通过已有语料库构建用户模拟器。强化学习的对话策略可以先在模拟器上训练到一个较合理的水平,再部署到真实环境中在线训练。
本文提出一种结合数据收集与基于规则的模拟器构建方式,模拟订电影票和电影咨询的任务,并演示了如何通过该框架来定制特定需求的模拟器。
关于任务型对话系统,相关结构可参考这篇博文。
相关工作
既然要搭建模拟器,首先要明白什么是一个好的模拟器。然而,“好”模拟器的标准目前学界也尚未统一,原则上
一个优秀的模拟器应该与真人的行为并无二致。
然而这并不可以量化什么,所以目前并无一种搭建用户模拟器的“标准”做法。
目前已知的用户模拟器大致可以如下分类:
- 按颗粒度:对话动作(
如:“提问地址”) 或 发言(如:“请问您想去哪儿看电影呢?”) - 按方法:基于规则(
也就是用代码逻辑写死了) 或 基于模型(也就是基于数据)
早期有通过连续两个动作的二元组来推导用户下一个行为的方法(也就是通过前一个动作预测后一个动作),但这样的用户模拟由于过于简单粗暴会产生不合逻辑的结果。
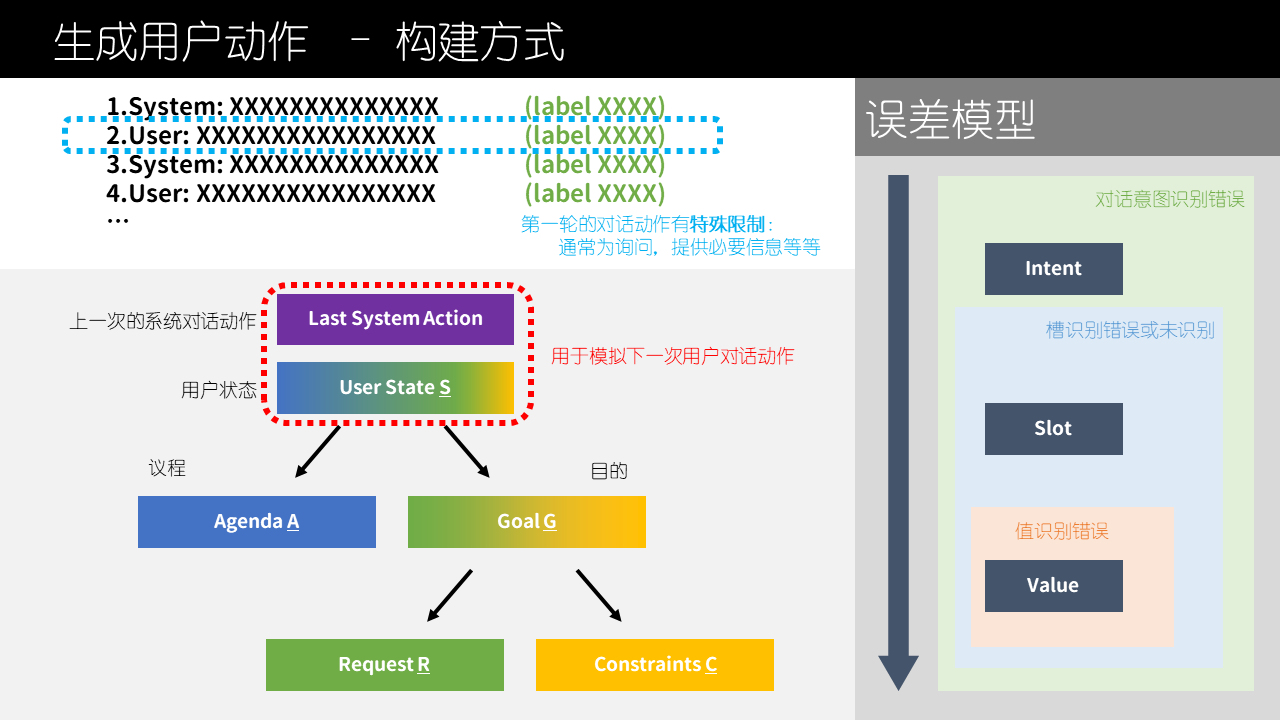
为了使得用户模拟器的行为更有逻辑,我们引入用户动作历史的记录以及用户目标的状态建模。
另一方面,最近也有使用序列到序列方法(seq2seq)来训练用户模拟器的工作。该类用户模拟器适用于聊天机器人,但在任务型对话表现较差,理由在于其无法满足任务型对话中查数据库,汇总信息等高度严密性为基于规则量身打造的工作。此外,该类用户模拟器虽然不需要特定的特征工程,但需要大量的标注数据,反正都得干。
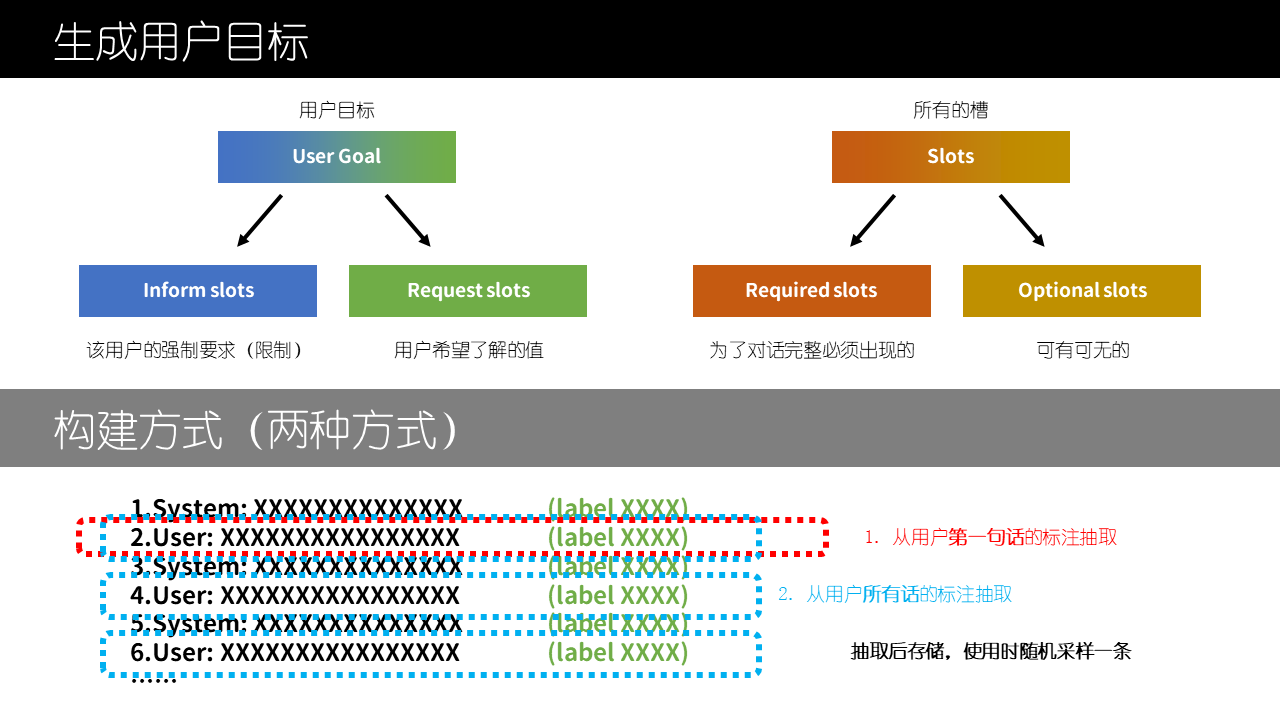
还有一种基于议程机制(agenda-based)的用户模拟器就清晰方便特别合适任务型对话。通过槽-值配对(slot-value pair)表格确定用户目标与限制;通过类似栈的结构记录用户行动来追踪对话状态以保证模拟的逻辑性。
本文用的就是这个特别合适的用户模拟器构建方式,通过议程机制解决对话动作的生成,通过序列到序列的自然语言生成(NLG)组件来将对话动作转换为自然语言。
本文使用的任务型对话系统
使用了Amazon Mechanical Turk的数据集以及自己设计的概要(schema)标了280轮对话(平均11轮)。
用户模拟器
关于Agenda-based可以参考这里的论文,其实大量的实现细节均取自该篇(值得一提的是,这篇论文描述的也是Pydial使用的用户模拟器)。

用户目标
用户动作
NLU与NLG
由于本文并未引入超出常规的方法(NLG中模板与模型结合算是一个改动),这两部分感兴趣的同学请自行观看。
结语
和引言差不多,略过一部分。项目其实有Github开源,实际看过感觉还是看代码比较有效率。
项目地址:TC-Bot
大家也去动手搭建自己的用户模拟器吧!话说谁会没事搭建这个…