神经网络欺骗是什么
引言
最近在上一门自选研究演讲的课程,给出的可选课题包含神经网络的欺骗(fooling)。我觉得听起来很好玩,也不是那种我能力不及的理论课题,所以就选了fooling。恰好队友之前也做过强化学习,所以商量着能不能用强化学习做一些尝试;上网一搜,发现去年(2018)的11月刚有一篇内容很像的东西刚挂arXiv预稿非常尴尬……仔细一看他们的结果好像也不是很好(人能明显察觉区别),就商量着能不能看看超过他们(然而做了一周多,结果还不如人家,这是后话……)。本篇主要介绍一些关于神经网络欺骗的我个人的理解,如有错误欢迎指出。
图像识别:神经网络的应用之一
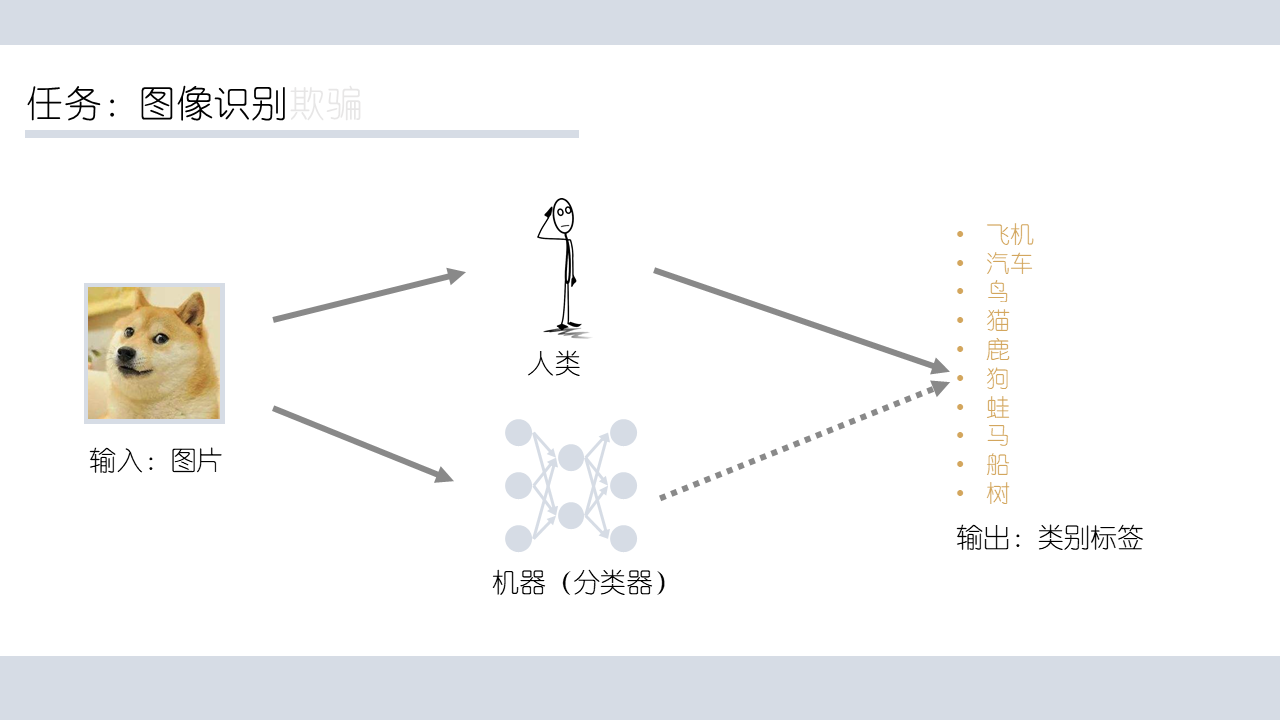
长久以来,人们一直希望让程序拥有理解图像的能力;特别的,能像三岁小孩儿一样认识猫狗动物以及自然。但是,“认识事物”是一个复杂的概念,作为一个简化版的问题,对于给定一些类别的图片,我们希望程序可以判断给定图片属于类别里的哪个。
比如我们这里有一只狗的图片,人类很轻易就能把它分类成狗,我们希望我们的机器,也就是分类器,能完成同样的任务。在这样的分类器中,神经网络作为一种拟合函数的常用手段,在多数分类任务中有着不俗的表现。
图像识别的欺骗
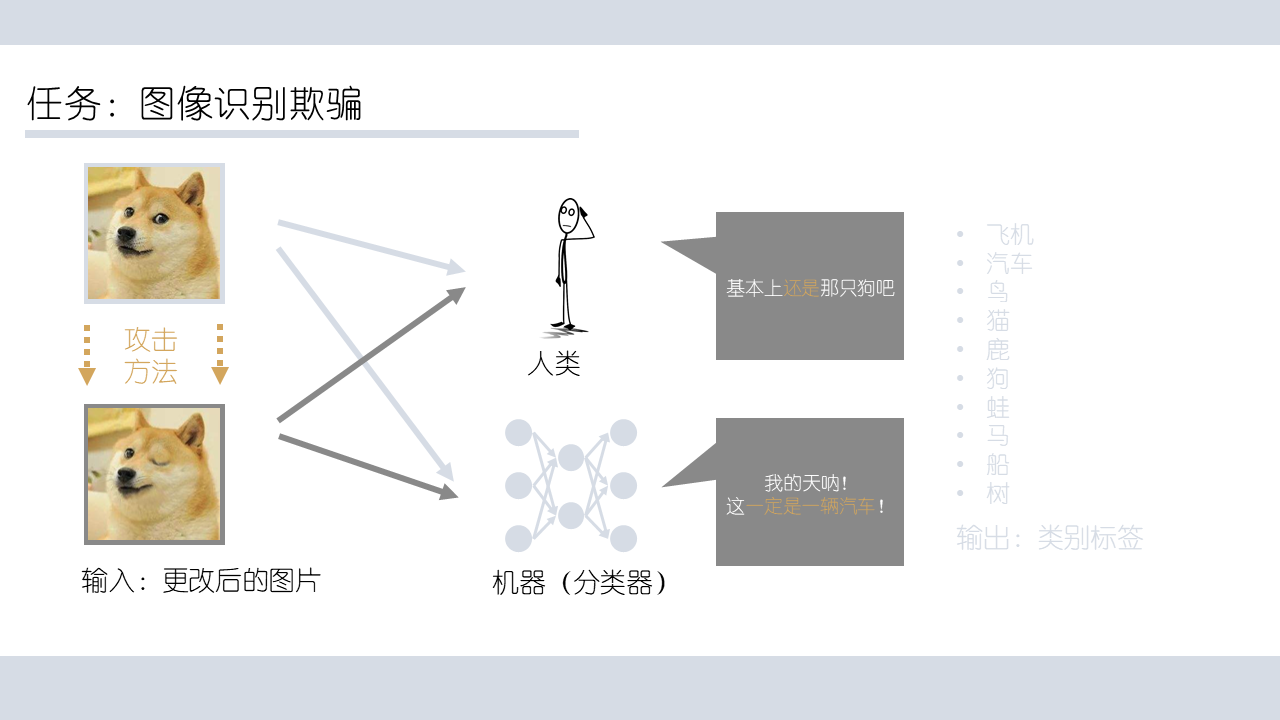
然而,这样的分类器程序存在着一个问题,那就是其分类方式本质上与人类还是有着很大差异,尤其是其对某些特征有病态的依赖性,这也使得攻击成为了可能。
根据这种差异,我们可以设计某种欺骗网络的攻击方法,使得对人类来说,图片的差异很小,但对训练好的网络来说,会大概率导致误分类;我们称这样的行为是对分类器的欺骗,特别的,在分类器是神经网络的情况下,这就是对于神经网络的欺骗。
然而更多研究表明,神经网络的脆弱性并不单纯的体现在图像分类这一任务上,单由于图像对人类而言更为直观,所以以其为例进行研究是一种较好的选择。
为什么要进行欺骗
举个例子,假设交通摄像头是通过神经网络识别车牌照的数字。如果我们有一种方法,使得对车牌照改变很小——交警看不出来,但使得分析街道数据的神经网络模型完全无法识别数字,那么这对于我们的交通管理是非常不利的。我们只有了解了欺骗的机制,才能有效的设计防御的方法。
另一个角度是研究欺骗有助于我们了解神经网络做分类的标准,其决策边界的一些性质。如果我们有一条面在高维输入空间划开两个分类,这条线会是什么样的呢?研究欺骗有助于我们通过构造样例穿过这个决策面,从而研究决策面这一边界本身的性质。
欺骗的原则
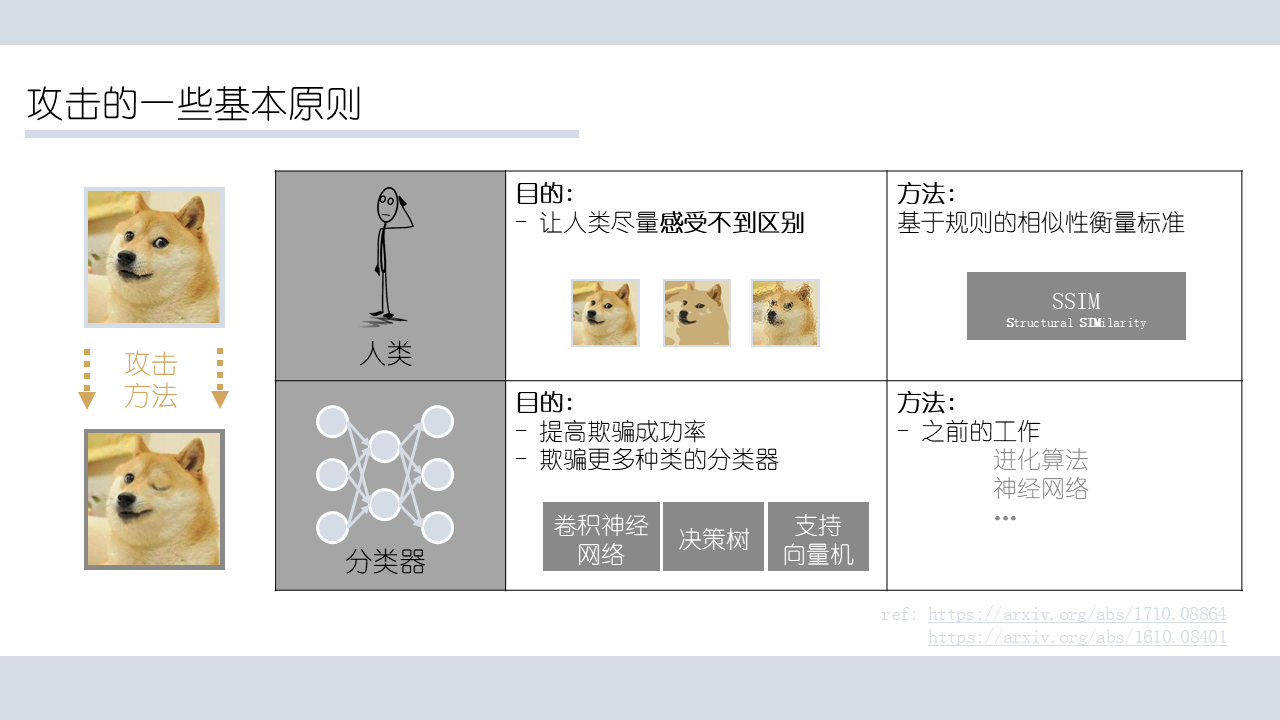
如何衡量欺骗是否优秀有两个指标:
- 是否对人来说没什么差别
- 是否对各种网络都容易骗到(成功率高)
相似性的比较上,作为常用指标的有各种p-范数(1-范数、2-范数、无穷范数)。我个人项目中用到的是,在图像压缩领域衡量压缩前后损失的一个常用指标叫做结构相似性(SSIM),感觉在衡量人的感官这一任务中效果更好。
而在欺骗成功率方面,之前有许多对图像识别欺骗的优秀研究,如对抗扰动(adversarial perturbation)的研究以及比较新颖的,单像素攻击(one-pixel attack)的研究等等都非常有趣,有兴趣的话可以搜索相关论文细读。
攻击的环境条件
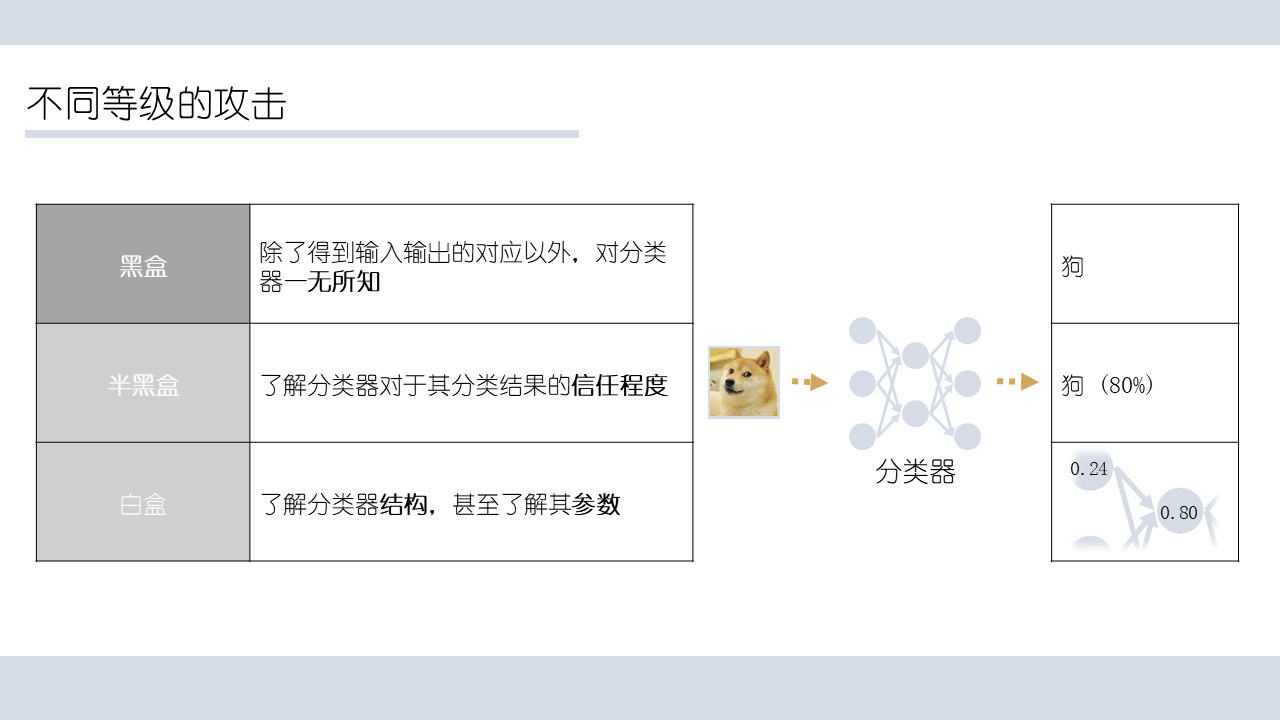
根据从困难到简单的环境设置,攻击方法本身也可以进行分类;分类的依据就是环境向攻击者透露模型的程度。
-
一般而言为了正常使用分类,攻击者可以得到输入和输出的对应;如果只能得到这一点,则称为是黑盒攻击。
- 如果攻击者能了解到分类器的自信程度(比如常见softmax的对应分类的结果),那么攻击者就可以利用其梯度来设计其攻击,这称为半黑盒攻击。
- 如果攻击者完全知晓分类器模型,甚至了解其超参数、参数,那么这种称为白盒攻击。
大多数攻击方法在测试时为了成功率与现实程度的权衡,都选择了半黑盒攻击作为挑战的对象。
结语
网络欺骗是个有趣的话题,然而,欺骗的数学依据是什么?它揭示了决策边界的什么性质?什么结构的网络容易被欺骗?怎样防御欺骗?我没弄懂的还有很多很多,所以这篇里也只能简要讲讲我了解到的内容。
希望之后我有时间能了解到更多,也欢迎对该问题感兴趣、有经验的同学与我交流。